Bishop: Makes Your Web Service Shiny
A couple of months ago I was working with another developer, he was building a web application around a web service that I had just finished writing. We were going over the API documentation that I put together and he straight-out asked me: “What happens if I send it something that’s not JSON?” I answered honestly: “I don’t know, but I bet it logs a really big stack trace!”
“What happens if I send it something that’s not JSON?”
“I don’t know, but I bet it logs a really big stack trace!”
Really, I should check the incoming “Content-Type” header that the client provided and if wasn’t JSON I shouldn’t even try to parse the data. That’s not so hard, but did I want to be re-writing that code for every project? And what about all of the other HTTP headers? To be honest, I didn’t even know what most of them were supposed to be doing.
Naturally this is a problem that’s been solved before. After doing some research I found Webmachine, which goes a long way towards handling all of the HTTP level stuff. Unfortunately for me, it’s written in Erlang and that means writing your service in Erlang; I really need to work with Java and Clojure. Still, not one to give up lightly, I began writing my own Webmachine-like library in Clojure and thus Bishop was born.
Table of Contents
More Than a Pipe Into Which You Shovel Data
After taking a closer look at HTTP and it’s specification, it was clear that it could do a lot more than I had thought. Looking back on past projects, it’s painfully obvious that I’ve been taking what is really an application protocol and ignoring all of the interesting bits, instead using it as little more than a pipe to push documents through. I’ve been using either the requested URL or parameters or maybe even neither and simply examined the body content, thus eliminating any of the real advantages of using HTTP in the first place.
And there are advantages. The protocol is already thinking about caching your data where it makes the most sense. There’s already an algorithm for taking the list of content types that the client wants and the content types the server provides and picking the best match. It can manage safe updating of resources as well as notifying the client of conflicts. And so on, by ignoring what the HTTP protocol has to offer I was making more work for myself.
What Does Bishop Do?
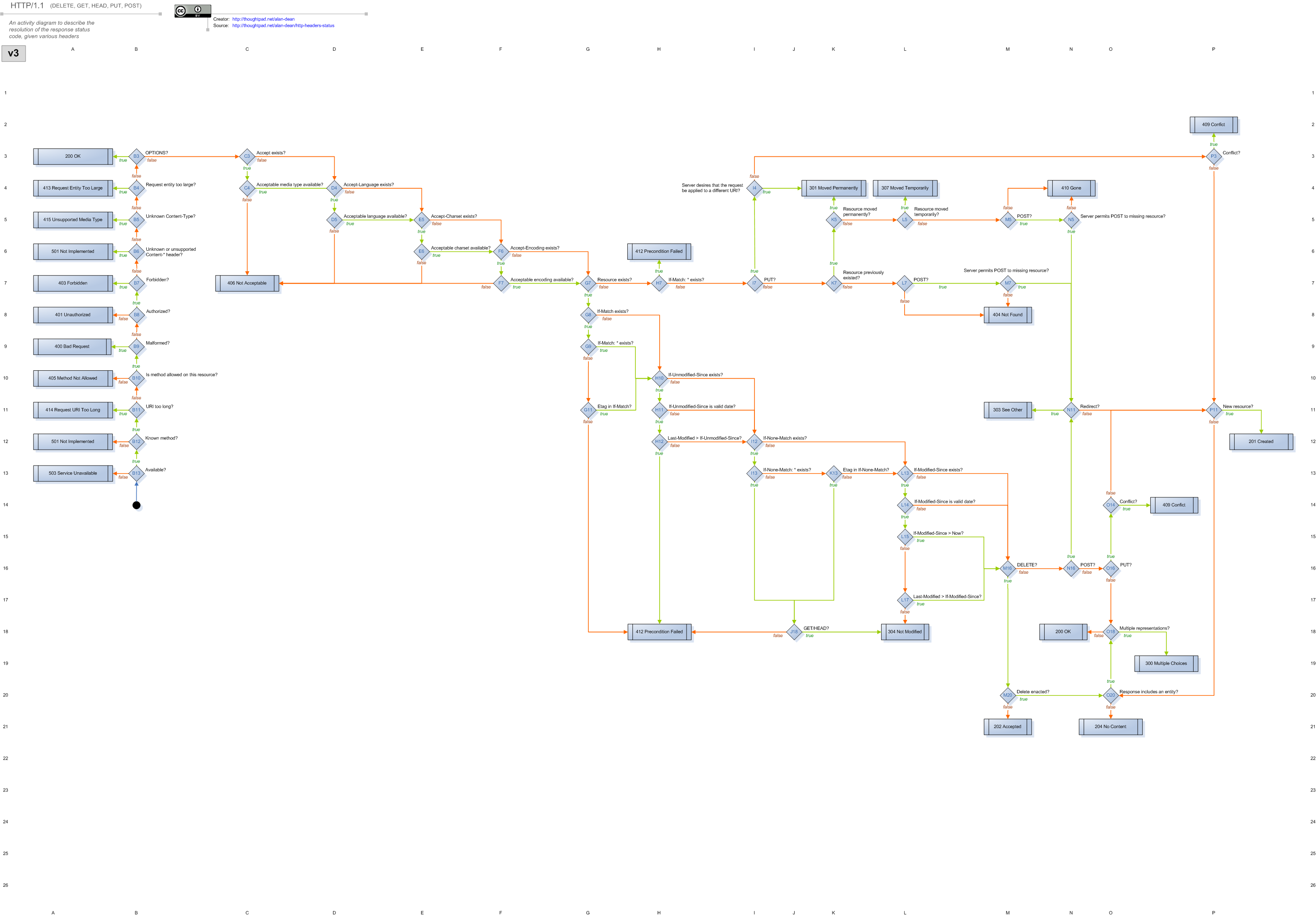
Like Webmachine, the Bishop library handles all of the HTTP protocol level stuff, you won’t have to spend a lot of time thinking about it. It does this by letting you code up a set of callback functions that the library will invoke as needed. For instance, when you’re using Bishop you can provide a function that lists the content types that your application knows about (i.e. “text/html”, “application/json”, etc.) and another that lists the request methods your application can handle (i.e. “GET”, “PUT”, etc.) Bishop will invoke the functions at the right time in order to negotiate with the client. When everything is all figured out (what content type to provide, if the URL points to a valid resource, etc.), your handler function is invoked and you can do whatever it is that your application does.
The idea is to provide a relatively small library that will make your life easier and hopefully more pleasant by making it straightforward to provide a consistent web service API that obeys HTTP semantics. It will make the lives of those around you easier as well, clients can expect your service to respond to the common HTTP request methods with reasonable responses. Placing caches around your service will also be much simpler and you’ll have some level of control over how your service’s data is cached.
How Do I Get Started with Bishop?
The Bishop library was designed to be small and easy to use. The basic idea is that you will code up a set of Bishop resources, each resource will correspond to a particular URL path. These resources will provide the necessary functions that Bishop needs in order to negotiate the request with the client and decide which handler function to invoke. Once that step is complete, your handler function will likely invoke a function or set of functions that provide the core functionality of your application; perhaps calling functions that add a record to a database or fetch data from your application.
We’ll wall through the sample application that accompanies the library and explain how the pieces fit together.
Add the Dependency
If you’re using Leiningen to manage your project, getting started is as easy as adding a dependency to your “project.clj” file.
(defproject bishop-sample "1.0" :description "A sample Bishop application" :dependencies [[org.clojure/clojure "1.3.0"] [ring/ring-core "1.0.2"] [ring/ring-jetty-adapter "1.0.2"] [cheshire "4.0.0"] [hiccup "1.0.0"] [tnrglobal/bishop "1.0.2"]] :dev-dependencies [[swank-clojure/swank-clojure "1.3.3"]] :main com.tnrglobal.bishopsample.core)
In the example above, we’re using Ring and Jetty to provide the web service, Cheshire to handle JSON parsing and Hiccup to provide HTML output. When you build your project, Leiningen will fetch all of these dependencies and anything they might depend on.
The Application
Next we need the application that we’ll be wrapping with our service interface. In this example we’ll be providing a simple to-do list with functions for listing all of the to-dos as well as adding, removing and updating items.
Each to-do item will be represented by a hash-map containing a title, description, the date it was created and the date of it’s last modification. First we setup a reference to hold our “database” of to-do items and we’ll start it off with one entry. I won’t go over this stuff function-by-function, you can take a look at the implementation here.
The Service
Each Bishop resource is defined with two hash-maps. The first provides a map of content types provided by the resource and the functions that accept a Ring request map and return data in that format. The second hash-map contains the key for a callback function and the actual function, these are invoked by Bishop when processing each request. You can view the complete list of callback functions here.
We can now work on developing the Bishop resources that will provide our web service. We’ll be using the “/todos” URL to provide both a list of to-do items (with a “GET”) and an end-point for requests to create new items (via “POST” or “PUT”). While this application deals with JSON data we also want to present a simple HTML interface for viewing the data. Listed below is our resource definition.
(def todo-group-resource (bishop/resource {;; JSON handler "application/json" (fn [request] (cond ;; return a sequence of to-do items (= :get (:request-method request)) {:body (generate-string (map (partial add-resource-links URI-BASE) (app/todos)))} ;; create the new to-do item (= :put (:request-method request)) (let [todo-in (parse-string (slurp (:body request)) true) todo (app/todo-add todo-in)] {:headers {"Location" (str URI-BASE "/" (:id todo))}}))) ;; HTML handler "text/html" (fn [request] {:body (xhtml {:lange "en" } [:body [:h1 "To-Do List"] [:ul (map #(todo-short-html (add-resource-links URI-BASE %)) (app/todos))]])})} {;; the request methods supported by this resource :allowed-methods (fn [request] [:get :head :post :put]) ;; POSTs with new data will be handled like a PUT :post-is-create? (fn [request] true) ;; we use the modification date on the most recently modified ;; to-do item as the modification date for the list of items :last-modified (fn [request] (app/most-recent-todo-modified))}))
The first map defines the content types our resource accepts and the functions that handle each type of request. Our first handler accepts JSON data and can handle either a “GET” or a “PUT” request. You can see that when the client fetches data we add resource links to each item and then use the resulting hash-map to create our JSON output. This output is then placed under the “:body” key of the response object. It the client is providing new to-do item data with a “PUT” request, we’ll parse that JSON data into a hash-map and add that item to our database. We’ll then redirect the client to the URL for the new to-do item.
Our second entry handles HTML content. When the client makes a “GET” request for HTML to our resource, we’ll provide an HTML listing of the items (including a link to the resource for each item). We don’t have to worry about parsing out the client’s headers and figuring out which type of content the client wants. Bishop handles that all of that for us.
We define our callback functions for our resource in the second hash-map, we provide the information that Bishop needs to handle incoming requests. We specify the methods that our resource can handle and instruct it to treat “POST” requests as if the client was doing a “PUT” for a new item. We also tell Bishop how to correctly generate the “Last-Modified” header.
There’s much more that Bishop can do for you, take a look at the rest of the code for this service. For instance, when you tell Bishop how to generate an “ETag” for your resource you make it easy for clients to fetch the entire resource only when it actually changes. If you run this sample application and point Google Chrome at it, you’ll notice that the first time you view a to-do item in the browser it fetches the item from the server. Subsequent fetches are served from Chrome’s local cache: Chrome uses the ETag header to do a conditional fetch and as long as the resource isn’t updated, Bishop responds with a “304 Not Modified.”
Setting up Routes and Starting the Server
Lastly, we need to set our application up with Ring and a server, in this example we use Jetty. First, our routes.
(def routes {["todos"] todo-group-resource ["todos" :id] todo-item-resource})
We’re using Bishop’s router, we indicate that everything with a “todos” URL should be directed at our group resource and anything in the form of “todo/???” should hit our item resource. The router provided is modeled after Webmachine, if you prefer another router you could simply use that instead.
Next we setup our Ring application. No magic here, we provide our routes (which point to Bishop resources) to our Bishop handler. We can then wrap that handler in any required middle-ware (none in this case) and hand that off to Jetty.
;; we setup our ring application (run-jetty (bishop/handler routes) {:port 3000})
Conclusion and Wrap-Up
The Bishop library provides the tools needed to easily create a web service that understands the semantics of HTTP. While this is something that you could always do on your own, the library makes it easy by encapsulating all of the logic required to understand the client’s request headers and then directing it to the correct handler on the application side. Under the covers Bishop implements finite state machine that models the HTTP protocol, ensuring that requests are handled the same way every time.
It is early days for this project, this is only the first release and I have no doubt that there are bugs to be uncovered! If you happen to spot any, please take the time to log an issue. Help of any kind is greatly appreciated and we’re looking forward to accepting pull requests.